Updated: | Originally published: | By Hayley Brown
Due to the abundance of data collected by organisations, it needs to be efficiently and effectively organised and stored to be beneficial to users. This is where data orchestration and data orchestration tools can help automate lengthy data processes.
As a result, data is collected and prepared for data analysis efficiently. It is now even more prevalent in the age of AI and LLMs being fed immeasurable amounts of data.
What is data orchestration?
Data orchestration is the process of collecting and organising data that is siloed from a number of different sources, making it accessible and preparing it for processing by data management and analysis tools. It allows you to automate and streamline your data-driven decision-making, as well as data fragmentation and integration.
Data Orchestration in the AI Era
In terms of AI data orchestration it isn’t just about moving data, it is about formatting data into context for Artificial Intelligence. Now data orchestration tools are now the ‘intelligence layer’ that dictates how data flows between SaaS applications and Large Language Models. They transform raw API responses into ‘clean, safe context’ that an AI agent can actually understand and act upon.
Why is data orchestration important?
Data orchestration is important for organisations for numerous reasons:
- Lowers costs
- Introduces and maintains compliance and security measures
- Ensures proper data governance
- Removes any data bottlenecks/silos
- Improves efficiency and experience
- Informs decision-making
Orchestration as an AI Gatekeeper
Data orchestration tools act as a security buffer between proprietary data and third-party AI models.
The problem is feeding raw customer data into public LLMs such as ChatGPT or Claude creates privacy and compliance risks. A solution to this is an orchestration layer that acts as a ‘gatekeeper’. It retrieves data, reformats it, redacts sensitive information, and handles authentication before the data is ever sent to the AI model.
The benefit of this is that it allows companies to ‘monetise safely’ by turning proprietary data into competitive AI advantages without risking data leakage.
What are data orchestration tools?
Data orchestration tools process data that is in different formats and transform it so it is in one standardised format. This results in faster data analysis.
For instance, simple data collection processes like capturing email addresses or dates, both of which can be collected in numerous ways can be reconciled. In regards to integration, data orchestration tools help users set up, test and publish integrations with ease.
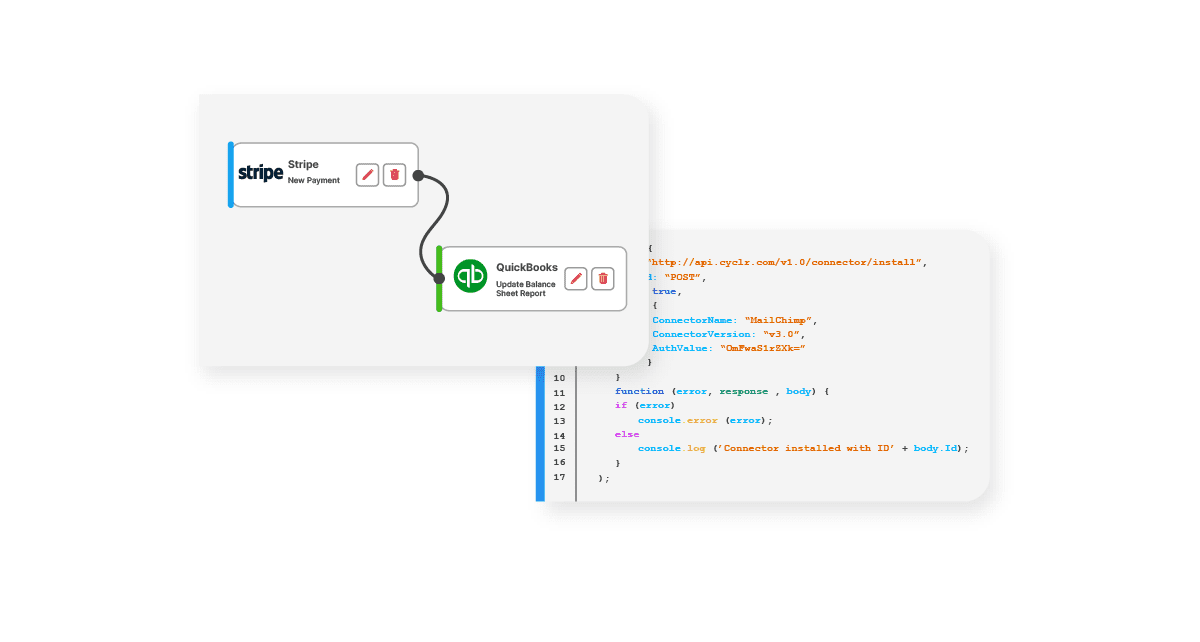
For example, Cyclr has an orchestration layer designed to allow users to create connections between APIs and third-party applications. This layer adds the ability to manage your data formatting so, you can format data separately between services. This is helpful when users’ requests and responses need to be split, merged or routed.
With drag-and-drop tools, users can create integrations and format the data to suit their needs or use cases. Tools such as field mapping, testing and templating help users develop workflows with ease.
As a result, the data is useful faster because it has been extracted, processed and made readily available across a number of SaaS applications in real-time.
Internal vs. Embedded Data Orchestration
Orchestration tools can differentiate depending on who is using them and the use case. For instance, IT teams for internal workflows would use a traditional iPaaS and tools used by SaaS vendors to offer integrations to their customers would be better suited to an embedded iPaaS.
- Internal: connecting your own marketing stack, for example Salesforce to HubSpot.
- Embedded: enabling your customers to connect their tools to your product.
- Multi-Tenancy: for B2B SaaS, orchestration must be multi-tenant. This means the tool can serve thousands of customers from a single platform while keeping every customer’s data, credentials and workflows strictly ring-fenced and segregated.
Cyclr’s Data Orchestration Tools
There is now a shift beyond the idea that only developers can do orchestration. Now modern orchestration tools like Cyclr provide low-code visual builders. These features empower end-users (the customers of the SaaS) to create their own ‘Agentic Workflows’ or ‘Custom MCP Servers’ directly inside the application.
In doing so this shifts the burden from the engineering team to the end-users, allowing ‘power users’ to innovate without draining internal developer resources. Below are just a handful of the useful data orchestration tools available in Cyclr.
MCP PaaS
Now, data orchestration is evolving into MCP PaaS (Platform as a Service), it is the standard that allows AI agents to reliably translate complex human intent into tangible, high-value product actions.
Traditional orchestration required building custom wrappers for every AI model. Now, using an orchestration tool with MCP capabilities allows a SaaS platform to ‘speak MCP natively’, making it instantly compatible with major models like Claude and ChatGPT.
It turns API endpoints in ‘MCP servers’ that can be deployed in minutes rather than months.

Discover Cyclr’s MCP PaaS
The Agentic framework is the new standard, discover how to move beyond custom API wrappers and establish your SaaS as an AI-Ready Platform.
Why Wait? Accelerate your AI Roadmap in Days, not Quarters.
Field Mapping
Field mapping allows users to map data from one app to another and then easily move that data between apps. So, whether your integrations are simple A to B or complex, multi-step processes your data with keep flowing in the field you mapped.

Testing
Testing tools are vital when you are building integrations and are important to be performed prior to the integration being published. Within integration builders, there is testing functionality allowing you to test and scrutinise your workflows to see the data flow. Transaction logs will help understand if any issues occur.
Templating
The beauty of building integrations is that they can be either custom-built or repeatable integration templates. Simply publish native integrations from within your application for end-users to use and repeat when needed.
Where does data normalisation fit in?
Data normalisation is a technical database operation performed with the goal to refine and associate similar forms of the same data into a single data form. It identifies data relationships and inputs the results into tables within a database to keep track of the price of items for example.
In simple data normalisation, the columns respond to an attribute of an object represented by the entire table. For instance, customers. The rows on the other hand represent a unique instance of that attribute and must be different from any other row. For example, what they bought.
This can then be further expanded into more columns. The data in the third column data is then dependent upon the data in the first two columns, for example, the price of the item the customer purchased.
Data normalisation has the ability to reduce data errors, redundancies and duplications. At the same time as improving data integrity. Data normalisation has become a key component of data development and is ideally incorporated after the data orchestration process to organise and unleash the data’s capabilities.
How do data orchestration tools help with data orchestration and integration?
Data orchestration tools provide your API and integration with advanced intelligence when communicating with other services. At the same time as handling security and authentication tasks.
Pre-built API connectors and low code data orchestration tools help users to rapidly integrate new data sources, and existing data silos. As well as automate end-to-end processes across an organisation, without having to develop new custom scripts.
Discover Cyclr’s MCP PaaS
The Agentic framework is the new standard, discover how to move beyond custom API wrappers and establish your SaaS as an AI-Ready Platform.
Why Wait? Accelerate your AI Roadmap in Days, not Quarters.



